



Software To Help You Turn Your Data Into AI
Forget fragmented workflows, annotation tools, and Notebooks for building AI applications. Encord Data Engine accelerates every step of taking your model into production.

The quality of a medical imaging dataset — as is the case for imaging datasets in any sector — directly impacts the performance of a machine learning model.
In the healthcare sector, this is even more important, where the quality of large-scale medical imaging datasets for diagnostic and medical AI (artificial intelligence) or deep learning models, could be a matter of life and death for patients.
As clinical operations teams know, the complexity, formats, and layers of information are greater and more involved than non-medical images and videos. Hence the need for artificial intelligence, machine learning (ML), and deep learning algorithms to understand, interpret, and learn from annotated medical imaging datasets.
In this article, we will outline the challenges of creating training datasets from medical images and videos (especially radiology modalities), and share best practice advice for creating the highest-quality training datasets.
Collaborative DICOM annotation platform for medical imagingCT, X-ray, mammography, MRI, PET scans, ultrasound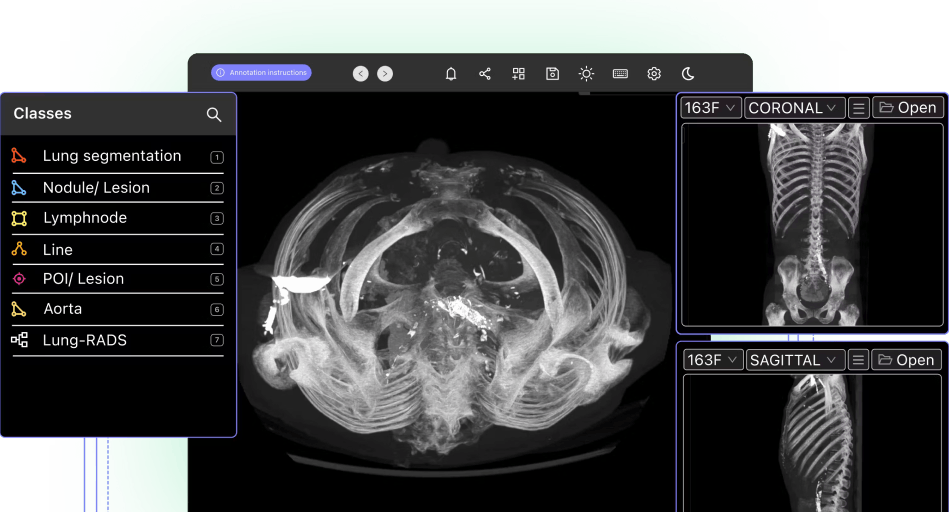
A medical imaging dataset can include a wide range of medical images or videos. Medical images and videos come from numerous sources, including microscopy, radiology, CT scans, MRI (magnetic resonance imaging), ultrasound images, X-rays (e.g. chest X-rays), and several others.
Medical images also come in several different formats, such as DICOM, NIfTI, and PACS. For more information on medical imaging dataset file formats:
Best Practice for Annotating DICOM and NIfTI Files
What's the difference between DICOM and NIfTI Files?
Medical image analysis is a complex field. It involves taking training data and applying ML, artificial intelligence, or deep learning algorithms to understand the content and context of images, videos, and health information to spot patterns and contribute to healthcare providers’ understanding of diseases and health conditions. Images and videos from magnetic resonance imaging (MRI) machines and radiologists are some of the most common sources of medical imaging data.
It all starts with creating accurate training data from large-scale medical imaging datasets, and for that, you need a large enough sample size. ML model performance correlates directly to the quality and statistically relevant quantity of annotated images or videos an algorithm is trained on.
A medical imaging dataset is created, annotated, labeled, and fed into machine learning (ML) models and other AI-based algorithms to help medical professionals solve problems. The end goal is to solve medical problems, using datasets and ML models to help clinical operations teams, nurses, doctors, and other medical specialists to make more accurate diagnoses of medical illnesses.
To achieve that end goal, it’s often useful to have more than one dataset to train an ML model and a large enough sample size. For example, a dataset of patients who potentially have health problems and illnesses, such as cancer, and a healthy set, without any illnesses. ML and AI-based models are more effective when they can be trained to identify diseases, illnesses, and tumors.
It’s especially useful when annotating and labeling large-scale medical imaging datasets, to have images that come with metadata as well as clinical reports. The more information you can feed into an ML model, the more accurately it can solve problems. Of course, this means that medical imaging datasets are data-intensive, and ML models are data-hungry.
Annotation and labeling work takes time, and there’s pressure on clinical operations teams to source the highest quality datasets possible. Quality control is integral to this process, especially when project outcome and model accuracy is so important
High-quality data should ideally come from multiple devices and platforms, covering images or videos of as many ethnic groups as possible, to reduce the risk of bias. Datasets should include images or videos of healthy and unhealthy patients.
Quality directly impacts machine learning model outcomes. So, the more accurate and widespread a range of images, and annotations applied, the more likely a model will train to a level of effectiveness and efficiency to make the project a worthwhile investment.
Annotators can create more accurate training data when they have the right tools, such as an AI-based tool that helps leading medical institutions and companies address some of the hardest challenges in computer vision for healthcare. Clinical operations teams need a platform that streamlines collaboration between annotation teams, medical professionals, and machine learning engineers, such as Encord.
Feeding a poor quality, poorly cleaned (cleansing the raw data is integral to this process), and inaccurately labeled and annotated dataset into a machine learning model is a waste of time.
It will negatively impact a model’s outcomes and outputs, potentially rendering the entire project worthless. Forcing clinical operations teams to either start again or re-do large parts of the project, costs more time and money, especially when handling large datasets.
The quality of a large dataset makes a huge difference. A poor-quality dataset could cause a model to fail, not to learn anything from the data because there’s insufficient viable material it can learn from.
Or if a model does train on an insufficiently diverse medical dataset it will produce a biased outcome. A model could be biased in numerous ways. It could be biased for or against men or women. Or biased for or against certain ethnic groups. A model could also inaccurately identify sick people as healthy, and healthy people as being sick. Hence the importance of a statistically large enough sample size within a dataset.
‘Bad’ data comes in many forms. It’s the role of annotation and labeling teams and providers to ensure clinical operations and ML teams have the highest quality data possible, with accurate annotations and labels, and strict quality control.
Common problems include imaging datasets that aren’t readable to machine learning models.
Hospitals sell large datasets for medical imaging research and ML-based projects. When this happens, images could be delivered without the diversity a model requires or stripped of vital clinical metadata, such as biopsy reports. Or hospitals will simply sell datasets in large quantities, without having the technical capability of filtering for the right images and videos.
However, an equally common problem is that medical data still includes identifiable personal patient information, such as names, insurance details, or addresses. Due to healthcare regulatory requirements and data protection laws (e.g. the FDA and European CE regulations), every image annotation project needs to be especially careful that datasets are cleansed of anything that could identify patients and breach confidentiality.
Other problems include using data from older models of medical devices, resulting in lower-resolution images and videos.
Creating and starting to annotate and label a medical image dataset involves overcoming some of these common challenges:
All of these questions need to be considered and answered before starting a medical image dataset annotation project. And only once images or videos have been annotated and labeled can you start training a machine-learning model to solve the particular problems and challenges of the project.
Now here are 7 ways clinical operations teams can improve the quality and accuracy of medical imaging datasets.
Scale your annotation workflows and power your model performance with data-driven insights
Before embarking on any computer vision project, you need to get the right data and it needs to be of a high enough quality and quantity for statistical weighting purposes. As we’ve mentioned, quality is so important, it can have a direct positive or negative impact on the outcomes of ML-based models.
Project leaders need to coordinate with machine learning, data science, and clinical teams before ordering medical imaging datasets. Doing this should help you overcome some of the challenges of getting ‘bad’ data or annotation teams having to sift through thousands of irrelevant or poor quality images and videos when annotating training data, and the associated cost/time impacts.
Regulatory and compliance questions need to be addressed before buying or extracting medical image datasets, either from in-house sources, or external suppliers, such as hospitals.
Project leaders and ML teams need to ensure the medical imaging datasets comply with the relevant FDA, European CE regulations, HIPAA, or any other data protection laws.
Regulatory compliance concerns need to cover how data is stored, accessed, and transported, the time a project will take, and ensuring the images or videos are sufficiently anonymous (without any specific patient identifiers). Otherwise, you risk breaking laws that come with hefty fines, and even the risk of data breaches, especially when working with third-party annotation providers.
Medical image annotation for machine learning models requires accuracy, efficiency, a high level of quality, and security.
With powerful AI-based image annotation tools, medical annotators and professionals can save hours of work and generate more accurately labeled medical images. Ensure your annotation teams have the tools they need to turn medical imaging datasets into training data that AI, ML, or deep learning models can use and learn from.
Clinical data needs to be delivered and transferred in an easily parsable format, easy to annotate, portable, and once annotated, fast and efficient to feed into an ML model. Having the right tools helps too, as annotators and ML teams can annotate images and videos in a native format, such as DICOM and NIfTI.
When searching for the ground truth of medical datasets, imaging modalities, and medical image segmentation all play a role. Giving deep learning algorithms a statistical range and quality of images alongside anonymized health information, dimensionality (in the case of DICOM images), and biomedical imaging data can produce the outcomes that ML teams and project leaders are looking for.
Viewing capacity is a concern that project leaders need to factor in when there are large volumes of images or videos within a medical imaging dataset. Do your annotation and ML teams have enough devices to view this data on? Can you increase resources to ensure viewing capacity doesn’t cause a blockage in the project?
As we’ve mentioned before, storage and transfer challenges also have to be overcome. Medical imaging datasets are often many hundreds or thousands of terabytes. You can’t simply email a Zip folder to an annotation provider. Project leaders need to ensure the buying or medical raw data extraction, cleansing, storage, and transfer process is secure and efficient from end to end.
When annotating thousands of medical images or videos, you need automation and other tools to support annotation teams. Make sure they’ve got the right tools, equipped to handle medical imaging datasets, so that whatever the quality and quantity they need to handle, you can be confident it will be managed efficiently and cost-effectively.
Encord has developed our medical imaging dataset annotation software in close collaboration with medical professionals and healthcare data scientists, giving you a powerful automated image annotation suite, fully auditable data, and powerful labeling protocols.
Ready to automate and improve the quality of your medical data annotations?
Sign-up for an Encord Free Trial: The Active Learning Platform for Computer Vision, used by the world’s leading computer vision teams.
AI-assisted labeling, model training & diagnostics, find & fix dataset errors and biases, all in one collaborative active learning platform, to get to production AI faster. Try Encord for Free Today.
Want to stay updated?
Follow us on Twitter and LinkedIn for more content on computer vision, training data, and active learning.
Join our Discord channel to chat and connect.

Join the Encord Developers community to discuss the latest in computer vision, machine learning, and data-centric AI
Join the communityRelated Blogs

In 1985, the PUMA 560 surgical robot made history by assisting the team at Memorial Medical Center during a stereotactic brain biopsy, marking one of the earliest recorded instances of robotic-assisted surgery and astonishing the world. Fast forward to today — surgical robotic systems are supporting surgeons across a growing array of medical interventions, assisting surgeries in ways few people imaged a few decades ago. Over the past eight years alone, the Robotically-Assisted Surgical (RAS) Devices market has expanded from $800 million in 2015 to well over $3 billion today. From prominent healthcare organizations to cutting-edge research institutes, from rapidly growing startups to non-profit initiatives, diverse teams are busy developing innovative surgical robotic systems. Their goal is to enhance surgical efficiency, improve precision and, ultimately, deliver better outcomes for patients. The recent leaps in computer vision have also further spurred this growth, as artificial intelligence is rapidly entering the operating room and enabling these systems to better perceive and interpret visual information in real time and aid surgeons on a wider range of tasks. This article explores the landscape of AI applications in surgical video analysis, some of the key innovators in the space and the role of high-quality training data in the development of AI-assisted surgical systems. AI-Assisted Surgical Robotics Companies like Intuitive Surgical, creator of the Da Vinci Surgical System, led the way in the 1990s: Da Vinci was the first robotics system approved by the FDA, initially for visualization and tissue retraction in 1997 and later for general surgery in 2000. With over 6,000 robots installed worldwide and over $6b in annual revenue, Intuitive has dominated the surgical robotics industry for the better part of the last 20 years, transforming the industry and enabling patient outcomes that were previously impossible. Yet 2019 marked the start of some of its patent expiries, and with that, a wave of new entrants and innovators. The use of AI-assisted techniques in robotics now extends from preoperative planning, to intraoperative guidance and postoperative care, and has advanced significantly thanks to the close collaboration of surgeons, programmers, and scientists. Let’s discuss some of the major real-world applications and teams working in this field — starting with preoperative planning. Preoperative planning Preoperative (pre-op) planning includes a range of workstreams — from visualizing the steps of the operation, to forming a plan to tackle navigation or improve precision. Machine learning and computer vision are being leveraged in pre-op planning in many ways: from rapidly analyzing the tabular and visual data of patients (like medical records or scans), to ensuring precise trajectory planning, optimizing incision sites, and gaining more insights into potential complications. Surgical planning begins with processing and fusing various medical imaging modalities, such as CT scans, MRI scans, and ultrasound scans, to generate a comprehensive 3D model of the patient's anatomy. Computer vision algorithms and deep learning models are then employed to quickly analyze this visual data and surface recommendations and risks with pursuing different surgical steps. Algorithms also enable surgeons to identify and segment specific anatomical structures and regions of interest from the imaging data (like organs, blood vessels, abnormalities, and other critical structures within the 3D model). This segmentation is crucial for surgical planning as it provides a clear visualization of the target area. From here, surgeons can explore different surgical approaches and plan the optimal trajectory for instruments and incisions, assessing the risk factors by quantifying the distance or overlap between the planned surgical path and nearby structures. Pre-op data can also be combined with intraoperative data to achieve surgical outcomes not otherwise possible. One of the most innovative end-to-end platforms is Paradigm™ by Proprio Vision, who just a few days announced the successful completion of the world's first light field-enabled spine surgery. Using an array of advanced sensors and cameras, Paradigm captures high-definition multimodal images during surgery and integrates them with preoperative scans to provide surgeons with real-time mapping of the anatomy. In addition to augmenting navigation capabilities during a procedure, Paradigm also collects large amounts of pre-op and intra-op data to inform future surgical decision-making and improve surgical efficiency and accuracy. You can read more about Proprio's announcement on their website here. Another end-to-end robotic system is Senhance, by Asensus Surgical, which in 2021 was cleared by the FDA for general surgeries. Senhance allows surgeons to create simulations for preoperative planning, while also providing real-time data for intraoperative guidance and generating insightful analytics for postoperative performance assessments and care. Intraoperative guidance A recent report by Bain & Company found that over 50% of surgeons surveyed made use of robotic systems in some capacity during general surgeries. During procedures, where even the slightest hand trembling can risk causing significant harm, image-guided surgery is turning into a requirement. Here, computer vision is often employed for instrument tracking and object recognition, which in turn are leveraged to feed video data to AI models that can monitor the procedure and generate guidance and warnings in case of anomalies, such as excessive bleeding or tissue damage. AI-assisted systems allow surgical robots to locate and follow the movement of surgical instruments, ensuring they are precisely positioned and maneuvered. They can also be used to identify critical structures and masses in the video footage, providing augmented guidance to the surgeon in real time. Model-assisted annotations of polyps in the Encord training data platform General and Minimally Invasive Surgery (MIS) Robotic assisted devices are more and more frequent in Minimally Invasive Surgeries (MIS). The primary objective of MIS is to reduce the trauma to the patient's body; the incision surface area is smaller, and often serves as an entry point, or port, for specialized instruments and a camera, known as a laparoscope, to enter the tissues and feed back real-time video data, which allows surgeons to view internal stuctures on a monitor and be guided through the procedure. MIS employs long, thin instruments with articulating tips that can be maneuvered through the small incisions. Systems like Dexter (by Distalmotion) are currently being used for daily gynecology, urology and general surgery procedures in Europe. “Surgeons can choose to operate entire procedures robotically, or they can leverage the ability to easily switch between the robotic and laparoscopic modalities to perform specialized tasks such as stapling with their preferred and trusted instruments,” Distalmotion CEO Michael Friedrich said in a recent press release announcing their upcoming US expansion. Another promising platform is Maestro (built by Moon Surgical), which sits at the intersection of robotic-assisted surgery and conventional surgery: acting as a robotic surgical assistant, it augments the precision and control of laparoscopic surgery, increasing the dexterity of a surgeon's own hand. Just this month, Moon Surgical announced the successful completion of the first 10 laparoscopic surgeries with its Maestro system in France. The procedures — bariatric and abdominal surgery procedures — were performed by laparoscopic surgeons Dr. Benjamin Cadière and Dr. Georges Debs, who said that the platform provided them with stability and precision that are difficult to match with human assistance. Many different procedure types are benefitting from the innovation in surgical assisted devices. A few examples are: Orthopedic Surgery. Orthopedic surgery is primarily used for the treatment of musculoskeletal conditions and disorders, mostly relating to bones and joints. With deep learning and computer vision, surgeons can build a pre-op model to plan the creation of patient-specific implants and the precise alignment of bones and joints, and then leverage a robotic arm to facilitate the optimal placement during the surgery. Stryker, the creators of the MAKO surgical assistant, are one of the pioneers in this space: MAKO turns a CT scan of a patient's joint into a 3D model, measures soft tissue balance, and, during surgery, ensures the placement is optimized to the patient's anatomy. Ganymed Robotics is another innovator in the space of orthopedic robotics. The Paris-based startup's team of computer vision and deep learning imaging experts have built a tool that leverages multimodal sensors to improve hard tissue surgery, starting with total knee arthroplasty (TKA). Robotic Bronchoscopy. Bronchoscopy helps evaluate and diagnose lung conditions, obtain samples of tissue or fluid, and remove foreign bodies. During a robotic bronchoscopy, the doctor uses a controller to operate a robotic arm, which guides a catheter (a thin, flexible, and maneuverable tube equipped with a camera, light, and shape-sensing technology) through the patient’s airways. Noah Medical received FDA clearance earlier this year for its Galaxy System™: a computer vision powered lung navigation system that improves the visualization and access of robotic brochoscopies. Microsurgery. Microsurgery requires the use of high-powered microscopes and precision instruments to perform intricate procedures on tiny structures within the body, such as blood vessel, nerve and tissue repairs. These kinds of surgeries operate hard-to-see anatomical structures that are often invisible to the human eye, and surgeons performing them need to undergo extensive training to develop exceptional hand-eye coordination. A handful of computer vision powered systems are being built to help improve the outcomes of these delicate surgeries, like MUSA-3, the microsurgery robot by Microsure, which allows surgeons to use a joystick to control instrument positioning during lymphatic surgery. The system is optimized for tremor-filtered movements and high-precision, and uses high-definition on-screen displays to enable real-time image analysis during these exceptionally delicate procedures. The Microsure team raised a €38m Series B earlier this month, as they eye FDA clearance in the US and CE-mark in Europe. Postoperative analysis and training Successful patient outcomes are achieved before, during, and after what happens in the operating room. AI surgical systems are valuable in post-operative analysis, as surgeons can review the process to understand improvement areas, identify potential health risks for the patient, and share insights to align expectations. Video data can also help trained newly formed surgeons, and provide education and knowledge share for the academic surgery community. Annotated surgical videos contain information regarding critical procedures, and can help inform students about effective surgical practices or risks involved with specific techniques. AI systems can also assess surgical performance by monitoring live video feeds and comparing a surgeon’s techniques with those used in similar procedures previously. The system can record custom metrics such as an operation’s total duration, patient satisfaction and post-operative complications, establishing benchmarks and shared understanding. A leader in this space is Orsi Academy, a Belgian training and research community that helps train medical professionals in new AI-driven techniques, such as computer vision for analyzing surgical videos, surgical data science for performance evaluation, and 3D printing, to simulation to help surgeons better understand and view specific body parts and surgical sites. Just a few days ago, Orsi Academy announced that their augmented reality tool (developed by Orsi Innotech) had enabled surgeons at Erasmus Medical Center to perform the world's first robot-assisted lobectomy using augmented reality, marking a huge achievement for the AI-assisted world of surgery. During this surgery, virtual overlay of the tumor, blood vessels and airways were projected over the camera image of the patient’s lung and was rendered with real-time AI-assisted robotic instrument detection. This allows surgeons to find their way inside the patient’s body more safely & effectively. Orsi Academy will be hosting their annual Orsi Event in Belgium, on December 14th and 15th. Details will be available on their website shortly.
October 25

The FDA has approved over 300 AI algorithms over the last 4 years – the vast majority of which relate to medical imaging. With the increase in medical AI and computer vision applications, healthcare teams are turning to AI models for more accurate and faster diagnosis at scale. A correct or incorrect diagnosis impacts treatment, care plans, and outcomes. And ultimately, computer vision and machine learning applications across medical AI have the potential to materially impact the chances of a positive outcome. And as we know, it all starts with data. Getting a radiology AI product to market – not to mention through FDA or CE clearance – starts with data quality and speed, which in turn relies heavily on accurate annotation and labels, whether the images come from CT, X-ray, PET, ultrasound, or MRI scans. To help you navigate all the DICOM labeling tools and frameworks on the market, we have compiled a list of the most popular annotation tools for annotating DICOM and NIfTI files. 💡Read more: Our Encord DICOM June product updates are out! Whether you are: A data science team at a fast-growing radiology AI startup trying to bring your first products to market or obtain FDA approval A data operations team at a large healthcare organization evaluating medical imaging tools to help your team analyze CT scans and MRI scans ...or a computer vision team at a healthcare provider or vendor delivering high-value machine learning-based solutions for hospitals, doctors, and other medical professionals. This guide will help you compare the top tools to annotate DICOM and NIfTI files and help you find the right one for you. We will compare them across a few key features – collaboration, quality control (QC) and quality assurance (QA), and ease of use for annotators and medical data operations managers. If you’re evaluating NIfTI labeling tools, you can find more about the key features you need to look out for here. So let’s get into it! In this post, we’ll cover six of the most popular AI-based medical image annotation tools: Encord DICOM 3D Slicer Labelbox Kili ITK-Snap MONAI Review of 6 Best Medical AI Annotation Tools for DICOM Encord DICOM Encord is the leading DICOM annotation platform trusted by leading medical AI teams at healthcare institutions. Encord’s AI-based annotation tool was purpose-built in close collaboration with healthcare teams for machine learning and computer vision projects in the medical profession. Encord and Encord Active are designed to handle vast medical image and video-based datasets (e.g. surgical video), alongside DICOM, NIfTI and +25 other data formats. Benefits & Key features: Native DICOM rendering: Render 20,000+ pixel intensities natively in the browser with a PACS-style interface. 3D views: Multiplanar reconstruction (axial, coronal, and sagittal views) and maximum intensity projection (MIP). Windowing support: Preset window settings for numerous modalities and the most common objects that need detecting, identifying, and annotating (e.g., lung, bone, heart, brain, etc.). Hanging protocols support: For Mammography, CT and MRI. Expert review workflows: Collaborative workflows designed for medical teams and scalable data operations. Foundation models support: Generate mask predictions with our AI-based auto-segment tool. Configurable labeling protocols: Create complex medical labels and protocols to train your annotation team with our medical-grade annotation tool. Support for multiple annotation types: Bounding boxes, polygons, segmentation, polylines, keypoints, object primitives, and classification. Best for: Teams rolling out new healthcare AI models, computer vision DataOps teams, annotation providers, ML engineers, and data scientists in medical organizations. Pricing: Free trial model and simple per-user pricing after that. 💡 More insights on labeling DICOM with Encord: Here are some examples of healthcare and medical imaging projects that Encord has been used for: Floy, a radiology AI company that helps radiologists detect critical incidental findings in medical images, reduces CT & MRI annotation time with AI-assisted labeling. RapidAI reduced MRI and CT annotation time by 70% using Encord for AI-assisted labeling. Stanford Medicine cut experiment duration time from 21 to 4 days while processing 3x the number of images in 1 platform rather than 3 Further reading: Best Practice for Annotating DICOM and NIfTI Files The 7 Features to Look Out For When Choosing a DICOM Annotation Tool 3D Slicer 3D Slicer is an open-source software application designed for medical image processing and visualization. It provides a platform for 3D image segmentation and registration. The US The National Institutes of Health (NIH) and other healthcare partners have played an important role in funding 3D Slicer, alongside Harvard Medical School, and dozens of other public and private funding sources. There have been numerous contributors to 3D Slicer, with an active community improving the source code, architecture, building modules, securing funding, and citing 3D slicer in medical computer vision and machine learning model training experiments and development. Benefits & Key features: Easy (& free) to get started labeling DICOM files. Great for manual data annotation — also supports semi-assisted labeling. Robust ground-level annotation capabilities (including classification and object detection) for a broad set of computer vision use cases. Best for: Students, researchers, and academics testing the waters with DICOM annotation (perhaps with a few files or a small open-source medical imaging dataset). Pricing: Free! 💡 More insights on image labeling with 3D Slicer: If your team is looking for a free annotation tool, you should know… 3D Slicer is one of the most popular open-source tools in the space, with over 1.2 million downloads since it was launched in 2011. Other popular free image annotation alternatives to 3D Slicer are CVAT, ITK-Snap, MITK Workbench, HOROS, OsiriX, MONAI and OHIF Viewer. If data security is a requirement for your annotation project… Commercial labeling tools will most likely be a better fit — as key security features like audit trails, encryption, SSO, and generally-required vendor certifications (like SOC2, HIPAA, FDA, and GDPR) are not available in open-source tools. Further reading: Buy vs build for computer vision annotation - what's better? Overview of open-source annotation tools for computer vision Labelbox Labelbox is a US-based data annotation platform founded in 2018, after the founders experienced the difficulties associated with building in-house ML operations tools. Like most of the other platforms mentioned in this guide, Labelbox offers both an image labeling platform, as well as labeling services. Teams can annotate a wide range of data types (PDF, audio, images, videos, and more) using the Labelbox data engine that can be configured for numerous ML, AI, and computer vision use cases. Benefits & Key features: Support for two annotation types – polyline and segmentation – and common imaging modalities – CT, MRI, and ultrasound. SaaS or on-premise workflows with privacy and security built-into the platform. Catalog view to help medical annotation teams label and sift and find patterns within vast multi-format datasets. Best for: Teams wanting to annotate other file formats alongside DICOM, like documents, video, text, audio, and PDFs. Pricing: 10,000 free LBUs to begin with, and custom pricing beyond that. 💡 More insights on labeling DICOM with Labelbox: If your team is looking for on-demand labeling services, you should know… Labelbox can connect your in-house team with outsourcing partners for large ML annotation projects. If data security is a requirement for your annotation project… Labelbox comes with enterprise-grade security as standard for healthcare and AI teams. Further reading: Top 10 Free Healthcare Datasets for Computer Vision 3 ECG Annotation Tools for Machine Learning Kili Kili is a data annotation platform founded in 2018 by a French team who had previously built the AI company, MyElefant, and an AI lab from scratch for BNP Paribas. The platform allows users to create and manage annotation projects, monitor progress, and collaborate with team members in real time. Kili has been used by businesses across various industries, including healthcare, finance, and retail, to accelerate their AI development. Benefits & Key features: Support for multiple annotation types, including text, image, video, and audio. A platform designed to label, find, and fix data annotation issues and simplify DataOps for AI teams of every size. For small-scale projects, DataOps can implement Kili with 5 lines of code to turn a machine learning workflow into a data-centric AI workflow. Best for: ML and DataOps teams across a range of sectors, either with in-house or outsourced teams. Pricing: Free tier for individuals, alongside corporate and enterprise plans for businesses. 💡 More insights on labeling DICOM with Kili: If your team is looking for an easy-to-integrate ML tool, you should know… Kili was designed to embed into ML workflows easily – it doesn’t have as many features as some computer vision SaaS products, but it integrates rapidly in a wide range of data tech stacks. Further reading: How to Annotate DICOM and NIfTI Files Medical Image Segmentation: A Complete Guide ITK-Snap ITK-Snap is a free, open-source, multi-platform software application used for image segmentation. ITK-Snap provides semi-automatic segmentation using active contour methods as well as manual delineation and image navigation. ITK-Snap was originally developed by a team of students at the University of North Carolina led by Guido Gerig (NYU Tanden School of Engineering) in 2004. Since then, it’s evolved considerably, now being overseen by Paul Yushkevich, Jilei Hao, Alison Pouch, Sadhana Ravikumar and other researchers at the Penn Image Computing and Science Laboratory (PICSL) at the University of Pennsylvania. The latest version, ITK-Snap 4.0, was released in 2020, funded by a grant from the Chan-Zuckerberg Initiative. Benefits & Key features: Manual segmentation in three planes. Support for additional 3D and 4D image formats alongside DICOM, like NIfTI. A 3D cut-plane tool for faster processing of image segmentation results and multiple images, including an advanced distributed segmentation service (DSS). Best for: Medical image annotation, students, and research teams. Pricing: Free! Further reading: 9 Best Image Annotation Tools for Computer Vision [2024 Review] The Top 6 Artificial Intelligence Healthcare Trends of 2024 MONAI MONAI is an open-source, PyTorch-based framework designed for deep learning in medical imaging. The project was started in 2019 by NVIDIA, the National Institutes of Health (NIH), and other contributors. The framework provides various tools, including a labeling tool, to assist in the creation of annotated datasets for training deep learning models. MONAI’s labeling tool allows users to annotate images with 2D or 3D bounding boxes, segmentation masks, and points. The annotations can be saved in a variety of formats and easily integrated into the MONAI pipeline for training and evaluation. MONAI has gained popularity due to its ease of use and its ability to accelerate research in medical imaging. Benefits & Key features: Easy (& free) to get started labeling biomedical and healthcare images with the MONAI Label Server. Capabilities for training AI models for healthcare imaging across a range of modalities and medical specialisms with two transformer-based architectures. Convenient integrations through the MONAI Deploy App SDK. Best for: Medical imaging, annotation, and research teams that need an open-source healthcare AI platform. Pricing: Free! 💡 More insights on labeling DICOM with MONAI: If your team is looking for an open-source alternative to commercial tools, you should know… MONAI is designed as an AI-based collaborative platform with a suite of features you can host and deploy in a wide range of medical environments. If data security is a requirement for your annotation project… MONAI is better equipped than most open-source medical imaging projects with layers of enterprise-grade security. Further reading: 7 Ways to Improve Medical Imaging Dataset Guide to Experiments for Medical Imaging in Machine Learning DICOM Annotation Tools: Key Takeaways There you have it! The 6 most popular annotation tools for annotating DICOM. For further reading, you might also want to check out a few honorable mentions, both paid and free annotation tools: Hive: Cloud-based AI tools for organizations that need to apply labels across a wide range of data types Dataloop: Software to train and improve ML and AI models with extensive annotation capabilities Appen: One of the oldest labeling services platforms on the market, launched in 1996 VOTT: An open-source tool with tags and asset export features compatible with Tensorflow and the YOLO format. Ready to improve the accuracy, outputs, and speed to get your healthcare AI models production-ready with DICOM annotations? Sign-up for an Encord Free Trial: The Active Learning Platform for Computer Vision, used by the world’s leading computer vision teams. AI-assisted labeling, model training & diagnostics, find & fix dataset errors and biases, all in one collaborative active learning platform, to get to production AI faster. Try Encord for Free Today. Want to stay updated? Follow us on Twitter and LinkedIn for more content on computer vision, training data, and active learning. Join our Discord channel to chat and connect.
July 4
6 min
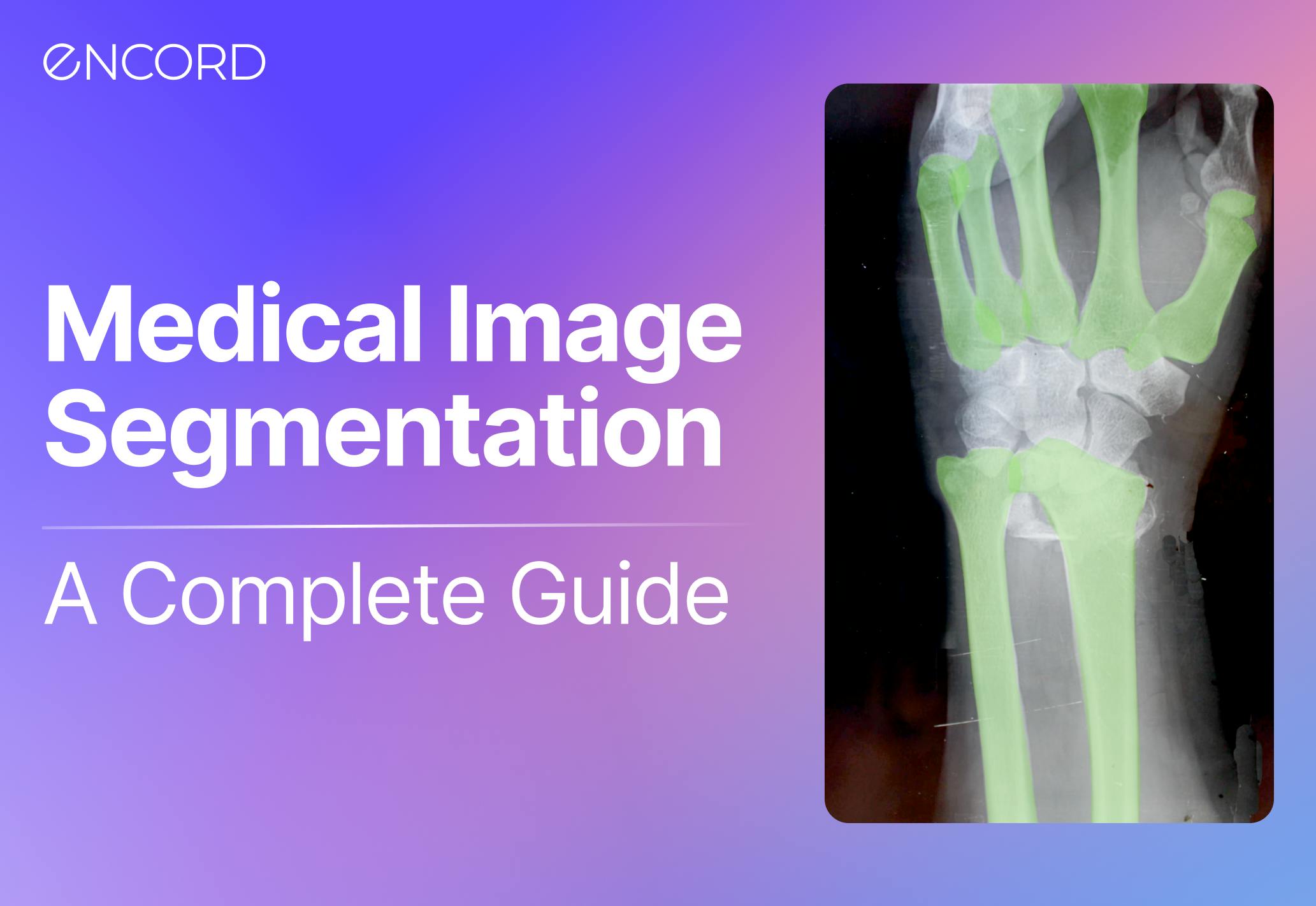
Medical image segmentation is used to extract regions of interest (ROIs) from medical images and videos. When training computer vision models for healthcare use cases, you can use image segmentation as a time and cost-effective approach to labeling and annotation to improve accuracy and outputs. Segmentation in medical imaging is a powerful way of identifying objects, segmenting pixels, grouping them, and using this approach to labeling to train computer vision models. In this guide, we’ll explore medical image segmentation, its role in healthcare computer vision projects, applications, and how to implement medical image segmentation. What is Medical Image Segmentation? Computer vision models rely on large training datasets used to train the algorithmic models (CV, AI, ML, etc.) to achieve high-precision medical diagnostics. An integral part of this process is annotating and labeling the images or videos in a dataset. One method for this is image segmentation, which this article will explore in more detail. Medical image segmentation involves the extraction of regions of interest (ROIs) from medical images, such as DICOM and NIfTI images, CT (Computed Tomography) scans, X-Rays, and Magnetic Resonance Imaging (MRI) files. There are numerous ways to approach segmentation, from traditional methods that have been around for decades to new deep-learning techniques. Naturally, everything in the medical profession needs to be implemented with precision, care, and accuracy. Any mistakes in the diagnosis or AI model-building stage could have significant consequences for patients, treatment plans, and healthcare providers. This guide is for medical machine learning (ML), data operations (DataOps), and annotation teams and leaders wanting to learn more about how they can apply image segmentation for their computer vision projects. Read more: Encord’s guide to medical imaging experiments and best practices for machine learning and computer vision. Why is Medical Image Segmentation used In Healthcare Computer Vision Models? Healthcare organizations, medical data operations, and ML teams can use medical image segmentation for dozens of computer vision use cases, including the following: Radiology Radiology is a medical field that generates an enormous amount of images (X-ray, mammography, CT, PET, and MRI), and healthcare organizations are increasingly turning to AI-based models to provide more accurate diagnoses at scale. Training those models to spot what medical professionals can sometimes miss, or identify health issues more accurately, involves labeling and annotating vast datasets. Image segmentation is one way to achieve more accurate labels so that models can go into production faster, producing the results that healthcare organizations need. Gastroenterology We can say the same about gastroenterology (GI) model development. Machine learning and computer vision models can be trained to more accurately identify cancerous polyps, ulcers, IBS, and other conditions at scale. Especially when it comes to outliers and edge cases that even the most skilled doctors and practice specialists can sometimes miss. Histology Medical image annotation is equally useful for histology, especially when AI models can accurately apply widely-used staining protocols (including hematoxylin and eosin stain (H&E), KI67, and HER2). Image segmentation helps medical ML teams train algorithmic models, implement labeling at scale, and generate more accurate histology diagnoses from image-based datasets. Ultrasound Image segmentation can help medical professionals more accurately label ultrasound images to identify gallbladder stones, fetal deformation, and other insights. Cancer Detection When cancerous cells are more difficult to detect, or the results from scans are unclear, computer vision models can play a role in the diagnosis process. Image segmentation techniques can be used to train computer vision models to screen for the most common cancers automatically, medical teams can make improvements in detection and treatment plans. Looking for a dataset to start training a computer vision model on? Here are the top 10 free, open-source healthcare datasets. Different Ways to Apply Medical Image Segmentation In Practice In this section, we’ll briefly cover 8 types of segmentation modes you can use for medical imaging. Here we’ll give you more details on the following types of image segmentation methods: Instance segmentation Semantic segmentation Panoptic segmentation Thresholding Region-based segmentation Edge-based segmentation Clustering segmentation Foundation Model segmentation For more information, check out our in-depth image segmentation guide for computer vision that also includes a number of deep learning techniques and networks. Instance segmentation Similar to object detection, instance segmentation involves detecting, labeling, and segmenting every object in an image. This way, you’re segmenting an object’s boundaries, and whether you’re doing this manually or AI-enabled, overlapping objects can be separated too. It’s a useful approach when individual objects need to be identified and tracked. Semantic Segmentation Semantic segmentation is the act of labeling every pixel in an image. This will provide a densely labeled image, and then an AI-assisted labeling tool can take these inputs and generate a segmentation map where pixel values (0,1,...255) are transformed into class labels (0,1,...n). Panoptic Segmentation Panoptic is a mix of the two approaches outlined above, semantic and instance. Every pixel is applied a class label to identify every object in an image. This method provides an enormous amount of granularity and can be useful in medical imaging for computer vision where attention to detail is mission-critical. Thresholding Segmentation Thresholding is a fairly simple image segmentation method whereby pixels are divided into classes using a histogram intensity that’s aligned to a fixed value or threshold. When images are low-noise, threshold values can stay constant. Whereas in noisy images, a dynamic approach for setting the threshold is more effective. In most cases, a greyscale image is divided into two segments based on their relationship to the threshold value. Two of the most common approaches to thresholding are global and adaptive. Global thresholding for image segmentation divides images into foreground and background regions, with a threshold value to separate the two. Adaptive thresholding divides the foreground and background using locally-applied threshold values that are contingent on image characteristics. Region-based Segmentation Region-based segmentation divides images into regions with similar criteria, such as color, texture, or intensity, using a method that involves grouping pixels. With this data, regions or clusters are then split or merged until a level of segmentation is achieved. Annotators and AI-based tools can do this using a common split and merge technique or graph-based segmentation. Edge-based Segmentation Edge-based segmentation is used to identify and separate the edges of an image from the background. AI tools can be applied to detect changes in intensity or color values and use this to mark the boundaries of objects in images. One method is the Canny edge detection approach, whereby a Gaussian filter is applied, applying non-maximum suppression to thin the edges and using hysteresis thresholding to remove weak edges. Another method, known as Sobel, involves computing the gradient magnitude and direction of an image using a Sobel operator, which is a convolution kernel that extracts horizontal and vertical edge information separately. Clustering Segmentation Clustering is a popular technique that involves grouping pixels into clusters based on similarities, with each cluster representing a segment. Different methods can be used, such as K-mean clustering, mean-shift clustering, hierarchical clustering, and fuzzy clustering. Visual Foundation Model Segmentation: (SAM) Segment Anything Model Meta’s Visual Foundation Model (VFM), called the Segment Anything Model (SAM), is a powerful open-source VFM with auto-segmentation workflows, and it’s live in Encord! It’s considered the first foundation model for image segmentation, developed using the largest image segmentation known, with over 1 billion segmentation masks. Medical image annotation teams can train it to respond with a segmentation mask for any prompt. Prompts can be asking for anything from foreground/background points, a rough box or mask, freeform text, or general information indicating what to segment in an image. Here’s how to use SAM to Automate Data Labeling in Encord. How to Implement Medical Image Segmentation for Healthcare Computer Vision with Encord With an AI-powered annotation platform, such as Encord, you can apply medical image segmentation more effectively, ensuring seamless collaboration between annotation teams, medical professionals, and machine learning engineers. At Encord, we have developed our medical imaging dataset annotation software in collaboration with data operations, machine learning, and AI leaders across the medical industry – this has enabled us to build a powerful, automated image annotation suite, allowing for fully auditable data and powerful labeling protocols. A few of the successes achieved by the medical teams we work with: Stanford Medicine cut experiment duration time from 21 to 4 days while processing 3x the number of images in 1 platform rather than 3 King’s College London achieved a 6.4x average increase in labeling efficiency for GI videos, automating 97% of the labels and allowing their annotators to spend time on value-add tasks Memorial Sloan Kettering Cancer Center built 1000, 100% auditable custom label configurations for its pulmonary thrombosis projects Floy, an AI company that helps radiologists detect critical incidental findings in medical images, reduces CT & MRI Annotation time with AI-assisted labeling RapidAI reduced MRI and CT Annotation time by 70% using Encord for AI-assisted labeling. Ready to automate and improve the quality, speed, and accuracy of your medical imaging segmentation? Sign-up for an Encord Free Trial: The Active Learning Platform for Computer Vision, used by the world’s leading computer vision teams. AI-assisted labeling, model training & diagnostics, find & fix dataset errors and biases, all in one collaborative active learning platform, to get to production AI faster. Try Encord for Free Today. Want to stay updated? Follow us on Twitter and LinkedIn for more content on computer vision, training data, and active learning. Join our Discord channel to chat and connect.
June 8
4 min
Software To Help You Turn Your Data Into AI
Forget fragmented workflows, annotation tools, and Notebooks for building AI applications. Encord Data Engine accelerates every step of taking your model into production.